My role: Senior Software Engineer
Project description: Designed and implemented a serverless AI pipeline to cluster large-scale datasets efficiently, enabling scalable data analysis without managing infrastructure.
Skills and deliverables
Overview
Designed and implemented a serverless AI pipeline to efficiently cluster large-scale datasets, processing over one million articles per day while enabling scalable and high performance data analysis.
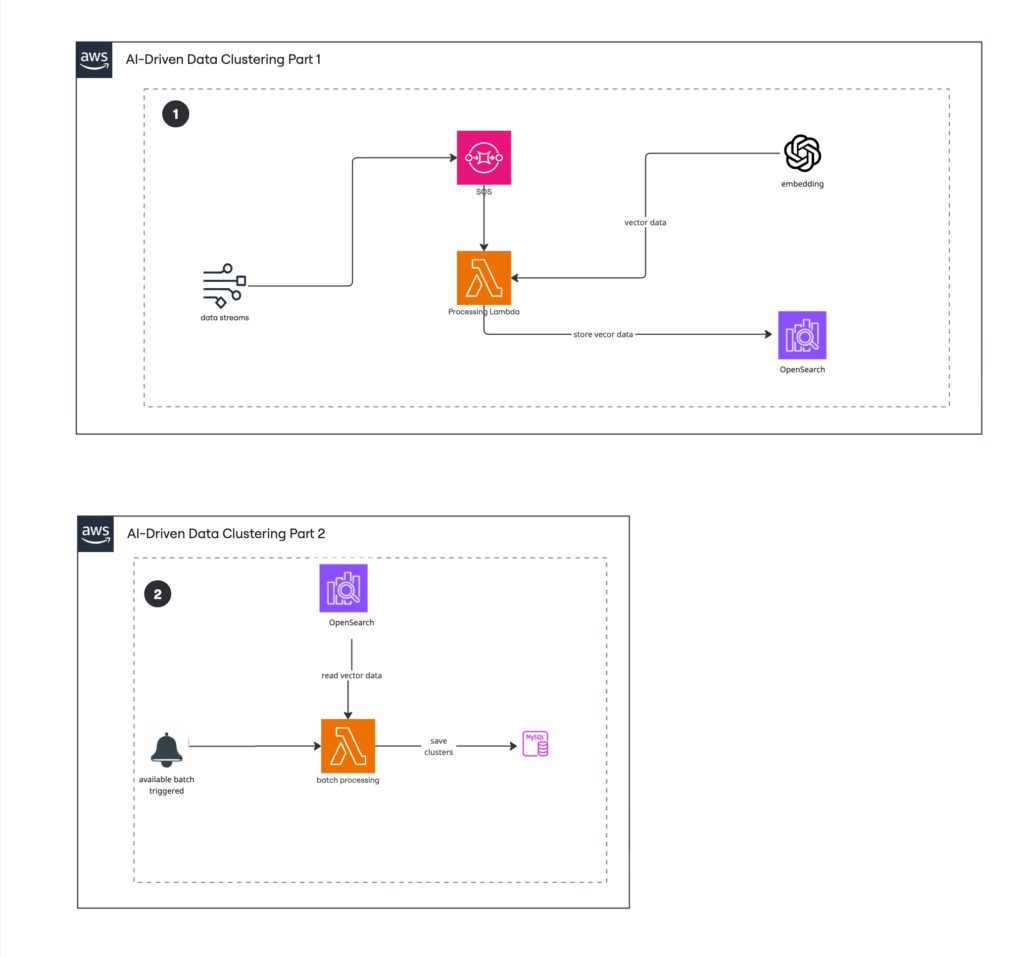
Problem
The system needed to process and cluster high-volume data with unpredictable workloads while keeping infrastructure costs low and scaling automatically.
Solution
Built a fully serverless architecture where data preprocessing and clustering tasks were distributed across AWS Lambda functions, orchestrated through event-driven workflows.
My Role
AI Engineer / Cloud Architect
Responsible for serverless system architecture, development, and performance optimisation.
Tech Stack
Python
AWS Lambda
AWS SQS
OpenSearch
OpenAI Embedding model
Machine learning clustering algorithms
Results
Data clustering significantly reduced operational costs for the client’s business when handling high-volume datasets.
Client
Private project